출처

데이터 불러오기 및 인덱스 지정
데이터를 읽어 오고 가장 먼저 할일은 첫 행 몇개와 마지막 행을 살펴보는 것이다. 그리고 유니크 식별값을 인덱스로 지정하고 dataframe 각 컬럼의 타입과 결측치 등을 파악하는 것이다.
# 데이터프레임 읽고 초반, 후반 행 확인하기
df = pd.read_csv("testset.csv", index_col=0)
df.head()
df.tail()
# 인덱스 지정
df.set_index("iduser", inplace=True)
# 컬럼별 type 확인 및 결측치 확인
df.info()
df.isnull().sum()
Plain Text
복사
결측치 처리
결측치 처리는 1) 결측치 사례 제거 2) 수치형의 경우 평균이나 중앙치로 대체(imputation)하거나 범주형인 경우 mode 값으로 대체 3) 간단한 예측 모델로 대체하는 방식이 일반적으로 이용된다. 가장 쉬운 방법은 Null이 포함 행 혹은 일부 행을 제거하는 것이다. 수집된 사례(observation)이 많다면 이 방법을 사용하는 것이 가능하다. 만약 샘플수가 충분하지 않을 경우, Pandas의 fillna() 명령어로 Null 값을 채우는 것이 가능하다. 연속형인 경우 Mean이나 Median을 이용하고 명목형인 경우 Mode(최빈치)나 예측 모형을 통해 Null 값을 대체할 수 있다.
데이터셋을 읽었다면, Missing Value 파악을 위해 df.info() 가장 처음에 이용하는 것을 추천한다. 만약 np.nan으로 적절히 missing value로 불러왔다면 info() 이용 가능하다. 만약 '', ' ' 이런식의 공백이나 다른 방식으로 처리되어 있다면, 모두 repalce 처리해줘야 한다. info()를 실행했을 때, 누가봐도 float or int 인데 object(string)으로 되어 있다면 이런 사레가 포함될 가능성이 높다.
결측치를 처리할 때 고려할 점
결측치를 처리할 경우에도 도메인 지식은 유용하게 사용된다.
인적, 기계적 원인임이 판명되면, 협업자와 지속적으로 노력해 결측치를 사전에 발생하지 않도록 조치하는 것이 좋다.
수치형인 경우 의미상으로 0으로 메꾸는 것이 맞는지 아니면 평균이나 중앙치가 맞는지 등은 데이터에 대한 배경지식이 있는 경우, 보다 적절한 의사결정을 할 수 있다.
예를 들어 viewCount가 1이상인데, edit, export가 missing인 경우 (도메인 지식을 통해) 0으로 메꾸는 것이 가능하다. View 가 다른 행동에 선행하는 개념이기 때문에 위와 같은 의사결정이 가능하다.
•
NA 와 Null 차이점 (R에서만 구분되는 개념, 파이썬에서는 numpy의 NaN만 이용, 가끔 pure python에서 None을 볼 수 있음, None = empty)
◦
NA: Not Available (does not exist, missing)
◦
Null: empty(null) object
◦
NaN: Not a Number (python)
◦
reference: https://www.r-bloggers.com/r-na-vs-null/
특히 숫자 0과 null 과 같은 결측치는 완전히 다른 개념이니 유의해야 한다. 만약 target(group)에 결측치가 있다면 imputation이 아닌 drop 으로 처리하도록 한다.
•
0: -1과 1 사이의 가운데 숫자(정수)
•
null: 미지의 값
# 결측치 부분을 메꾸는 방법
test['viewCount'] = test['viewCount'].fillna(test.viewCount.mean())
# 만약 결측치가 문자열 스페이스(' ')로 되어 있다면, np.nan으로 바꾸어 Pandas 라이브러리가 인식할수 있도록 변환
test.viewCount = test.viewCount.replace('', np.nan)
# 결측치를 제거하는 방법
test.dropna(how='all').head() # 한 행이 모두 missing value이면 제거
test.dropna(how='any').head() # 한 행에서 하나라도 missing value가 있으면 제거
Plain Text
복사
이상치 처리
일반적으로 1) 표준점수로 변환 후 -3 이하 및 +3 제거 2) IQR 방식 3) 도메인 지식 이용하거나 Binning 처리하는 방식이 이용된다. 표준점수 이용할 경우 평균이 0, 표준편차가 1인 분포로 변환한후 +3 이상이거나 -3 이하인 경우 극단치로 처리한다.
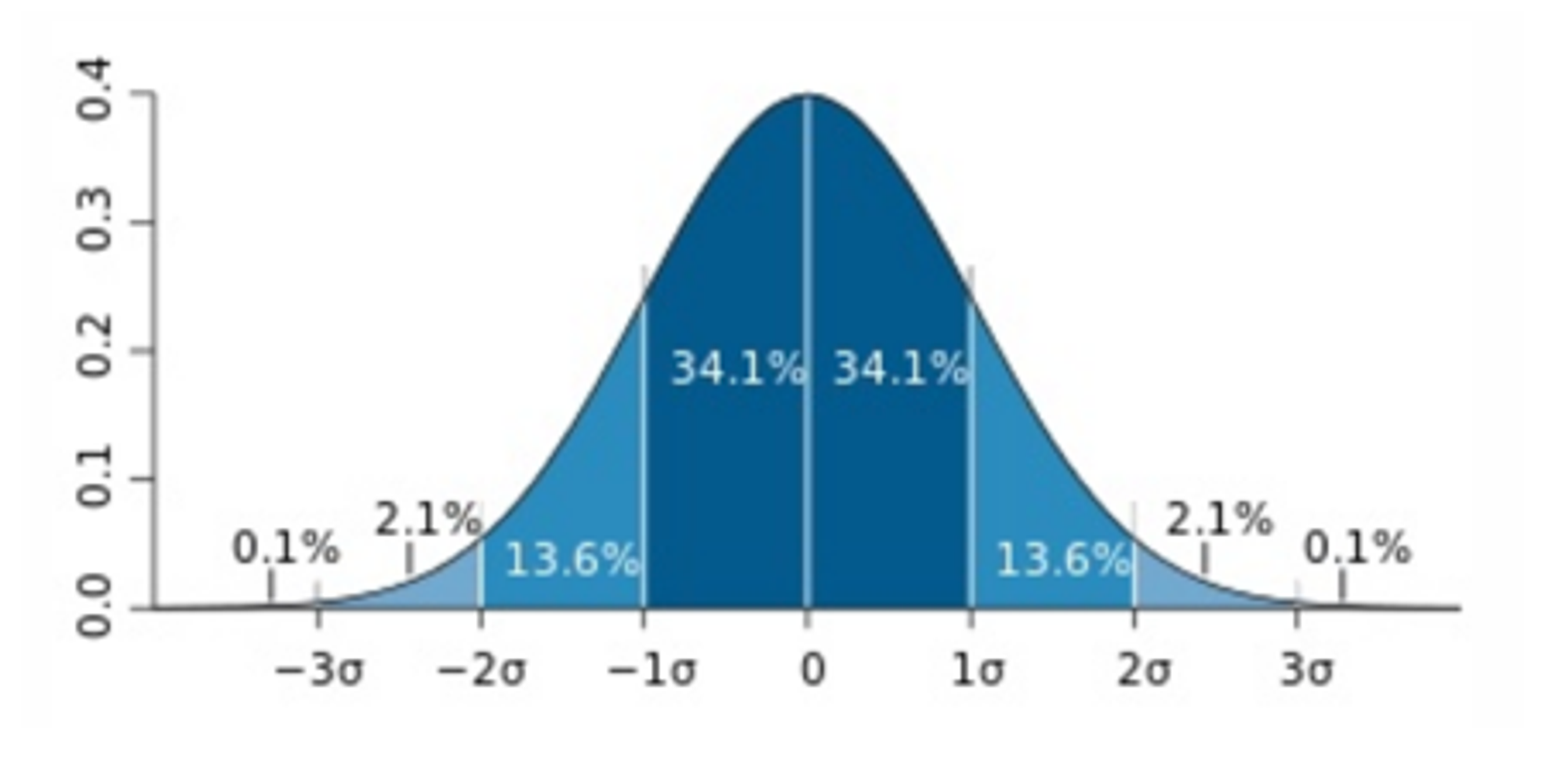
Source: Wikipedia
# 표준점수 기반 예제 코드
defstd_based_outlier(df):
for iin range(0, len(df.iloc[1])):
df.iloc[:,i] = df.iloc[:,i].replace(0, np.NaN) # optional
df = df[~(np.abs(df.iloc[:,i] - df.iloc[:,i].mean()) > (3*df.iloc[:,i].std()))].fillna(0)
Plain Text
복사
IQR 방식은 75% percentile + 1.5 * IQR 이상이거나 25 percentile - 1.5 * IQR 이하인 경우 극단치로 처리하는 방식이다. 이해하기 쉽고 적용하기 쉬운 편이지만, 경우에 따라 너무 많은 사례들이 극단치로 고려되는 경우가 있다.
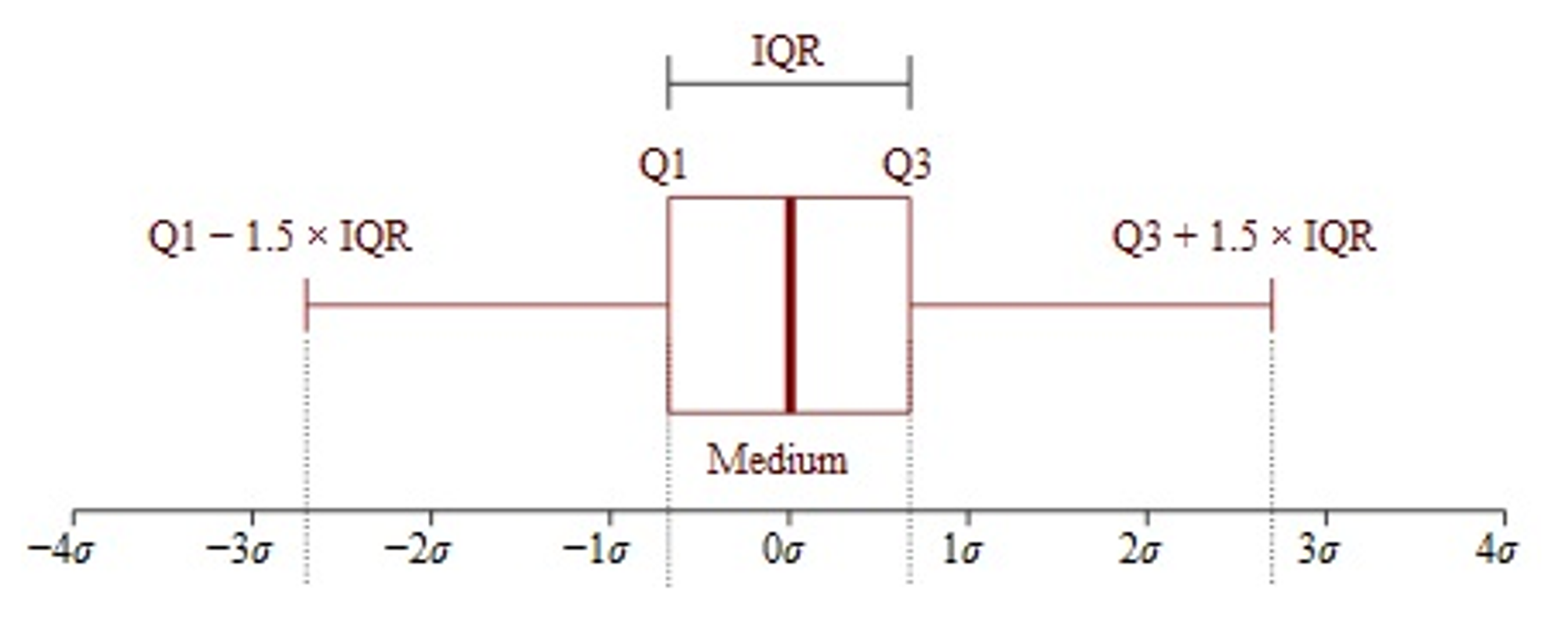
Source: statisticshowto
# IQR 기반 예제 코드
defoutliers_iqr(ys):
quartile_1, quartile_3 = np.percentile(ys, [25, 75])
iqr = quartile_3 - quartile_1
lower_bound = quartile_1 - (iqr * 1.5)
upper_bound = quartile_3 + (iqr * 1.5)
return np.where((ys > upper_bound) | (ys < lower_bound))
Plain Text
복사
데이터 분포 변환
대부분의 모델은 변수가 특정 분포를 따른다는 가정을 기반으로 한다. 예를 들어 선형 모델의 경우, 설명 및 종속변수 모두가 정규분포와 유사할 경우 성능이 높아지는 것으로 알려져 있다. 자주 쓰이는 방법은 Log, Exp, Sqrt 등 함수를 이용해 데이터 분포를 변환하는 것이다.
import math
from sklearnimport preprocessing
# 특정 변수에만 함수 적용
df['X_log'] = preprocessing.scale(np.log(df['X']+1)) # 로그
df['X_sqrt'] = preprocessing.scale(np.sqrt(df['X']+1)) # 제곱근
# 데이터 프레임 전체에 함수 적용 (단, 숫자형 변수만 있어야 함)
df_log = df.apply(lambda x: np.log(x+1))
Plain Text
복사
위 방법 외에도 분포의 특성에 따라 제곱, 자연로그, 지수 등 다양한 함수가 사용될 수 있다. 가이드는 아래와 같다.
•
left_distribution: X^3
•
mild_left: X^2
•
mild_right: sqrt(X)
•
right: ln(X)
•
servere right: 1/X
데이터 단위 변환
데이터의 스케일(측정단위)이 다를 경우 특히 거리를 기반으로 분류하는 모델(KNN 등)에 부정적인 영향을 미치므로, 스케일링을 통해 단위를 일정하게 맞추는 작업을 진행해야 한다. 아래 방식이 주로 스케일링을 위해 쓰이는 방법이다. 대부분의 통계 분석 방법이 정규성 가정을 기반으로 하므로 완벽하지 않더라도 최대한 정규분포로 변환하는 노력이 필요하다.
•
Scaling: 평균이 0, 분산이 1인 분포로 변환
•
MinMax Scaling: 특정 범위 (예, 0~1)로 모든 데이터를 변환
•
Box-Cox: 여러 k 값중 가장 작은 SSE 선택
•
Robust_scale: median, interquartile range 사용(outlier 영향 최소화)
from scipy.statsimport boxcox
# 변수별 scaling 적용
df['X_scale'] = preprocessing.scale(df['X'])
df['X_minmax_scale'] = preprocessing.MinMaxScaler(df['X']
df['X_boxcox'] = preprocessing.scale(boxcox(df['X']+1)[0])
df['X_robust_scale'] = preprocessing.robust_scale(df['X'])
# 데이터 프레임 전체에 scaling 적용
from sklearn.preprocessingimport StandardScaler
from sklearn.preprocessingimport MinMaxScaler
# StandardScaler
for cin df:
df_sc[c] = StandardScaler().fit_transform(df[c].reshape(-1,1)).round(4)
# MinMaxScaler
for cin df:
df_minmax[c] = MinMaxScaler().fit_transform(df[c].reshape(-1,1).round(4))
Plain Text
복사
안녕하세요
•
한국전자기술연구원 김영광입니다.
•
관련 기술 문의와 R&D 공동 연구 사업 관련 문의는 “glory@keti.re.kr”로 연락 부탁드립니다.
Hello
•
I'm Yeonggwang Kim from the Korea Electronics Research Institute.
•
For technical and business inquiries, please contact me at “glory@keti.re.kr”